Nanci
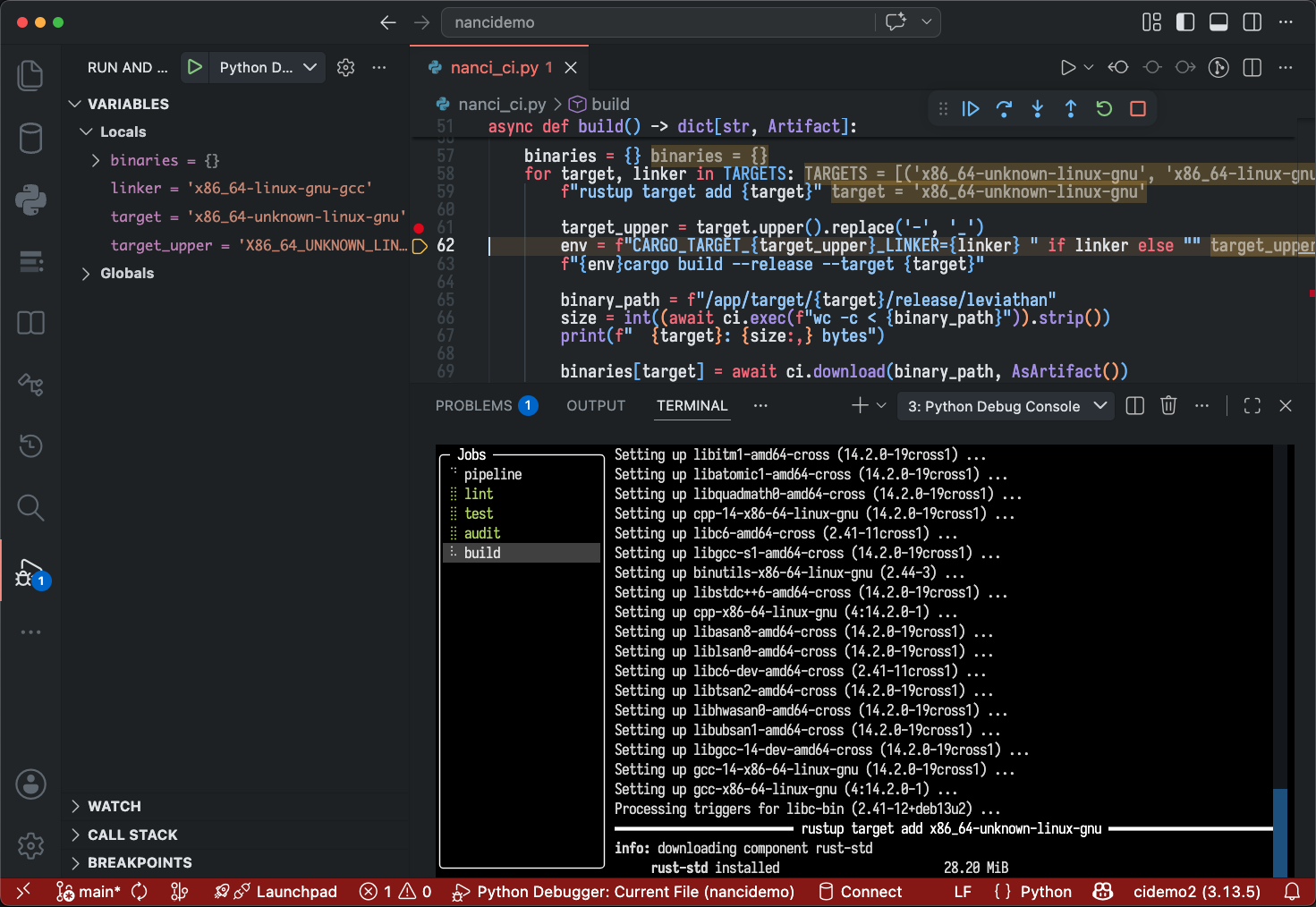
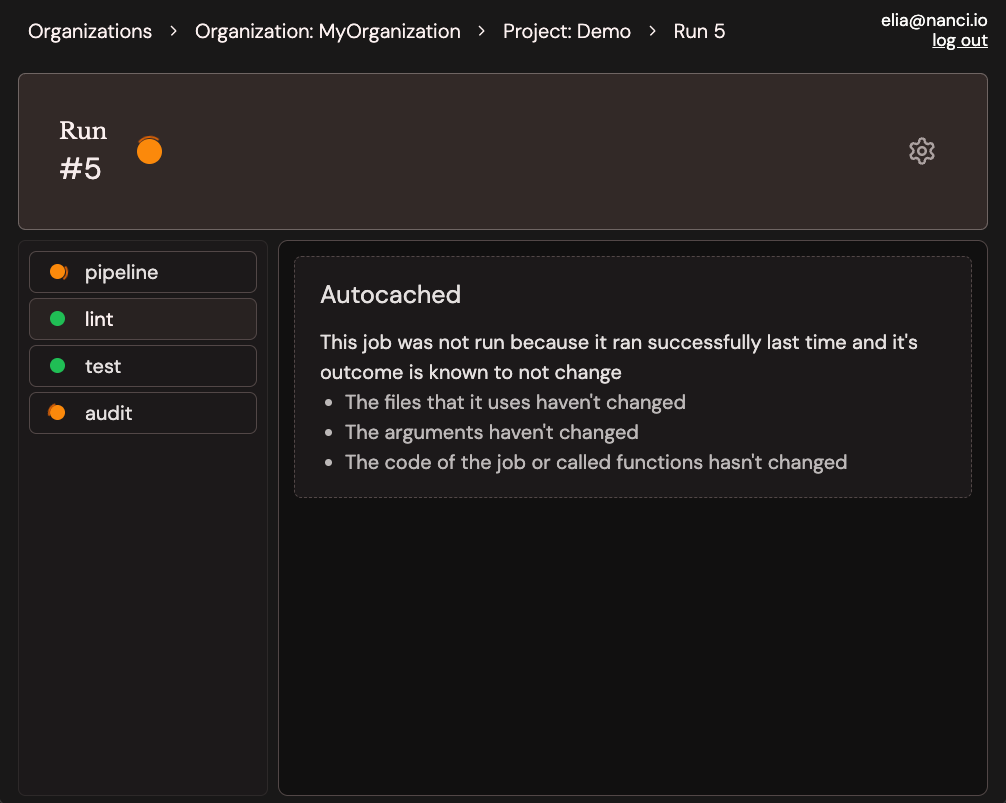
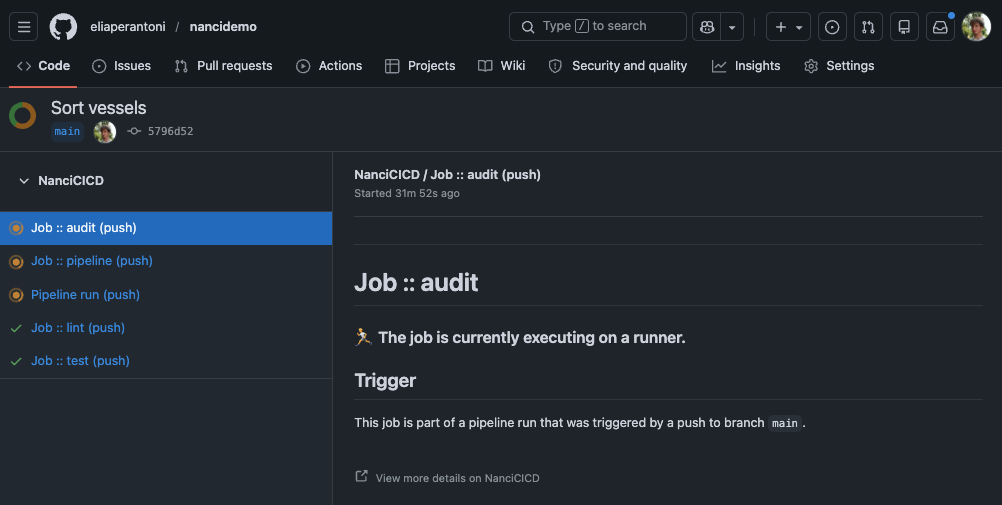
ci without the git commit -m 'try fix ci' over and over ci where if it passes locally, it passes in the cloud ci where build artifacts are just return values ci where env vars and cwd stay put between commands ci where @autocache decides when to rerun, so you don't have to ci you can step through with a debugger ci where jobs are just async functions ci you can debug on your laptop ci written in plain Python ci that fits in one Python file ci where the tests that didn't change don't run ci without the YAML headaches